09: Backend
Ihr wisst jetzt alles, was ihr braucht, um das Frontend einer Anwendung zu schreiben, aber wann immer ihr diese Anwendung schließt, ist alles weg – wie wir Daten auch über mehrere Sitzungen hinweg speichern können und warum man dazu nicht zwingend einen Backend-Server braucht, besprechen wir in dieser Session.
Inhalt
Wie kann man Daten "persistent" abspeichern?
Wenn ihr in JavaScript, oder dem Browser ein Programm ausführt, wird es in den Arbeitsspeicher (RAM) eures Computers geladen. Das bedeutet, alle eure Variablen und anderen Daten befinden sich im Arbeitsspeicher und da der Arbeitsspeicher ein sogenannter „flüchtiger“ Speicher ist, werden die Daten daraus wieder entfernt, sobald sie nicht mehr gebraucht werden. Das ist spätestens dann der Fall, wenn die Ausführung eures Programms beendet wurde, z.B. durch das Schließen des Browsertabs.
In vielen Fällen ist das gar kein Problem, wenn wir zum Beispiel auf einer Videoplattform wie YouTube ein Video ansehen wollen, öffnen wir die Seite in unserem Browser, schauen uns das Video an und schließen den Tab oder das Fenster wieder, wenn wir fertig sind. Da macht es wenig Sinn, wenn wir YouTube das nächste Mal aufrufen wieder beim selben Video zu landen, das wir schon vollständig angesehen haben und es wäre auch alles andere als Ideal, wenn all die Videos, die wir uns jemals angesehen haben in unserem Arbeitsspeicher bleiben würden. Kurzum: in den meisten Fällen ist es also in Ordnung, wenn die Daten weg sind, sobald wir das Fenster schließen.
Aber für unsere Todo-Apps ist das alles Andere als okay. Denn der Nutzer soll ja seine Todos anlegen und auch beim nächsten Öffnen wieder sehen können, ansonsten bräuchte er/sie die Aufgaben ja gar nicht aufschreiben. Wir brauchen also einen Weg diese Daten aus dem flüchtigen Arbeitsspeicher in den nicht flüchtigen Festplattenspeicher zu verschieben. Daten, die sich dort auch nachdem die Anwendung nicht mehr ausgeführt wird noch befinden, nennt man persistente Daten.
Nun wäre es aber sehr ungünstig, wenn jede Webseite einfach beliebig Daten auf unseren Festplatten lesen und schreiben könnten, denn das wäre ein gewaltiges Sicherheitsproblem – überlegt euch mal, was passieren könnte, wenn eine Website wie Facebook oder Google ohne eure Erlaubnis einfach alle Bilder auf eurem Gerät auslesen könnte. Deshalb existiert jeder Tab in eurem Browser, und auch jede installierte PWA in einer eigenen „Sandbox“, also einem fest begrenzten Teil des Arbeitsspeichers, der nicht einfach so Zugriff auf den Rest der Daten hat.
Um dann auf sensible Bereiche wie die Festplatte, oder Gerätesensoren zugreifen zu können, braucht es die Erlaubnis des Nutzers – oder eine API, die es möglich macht, diese Funktionen in einem sicheren Umfeld zu verwenden.
Im Hinblick auf persistente Daten gab es in den vergangenen Jahren viele verschiedene Ansätze, von denen sich bisher nur drei wirklich gehalten haben: Cookies, LocalStorage, und IndexedDB. Aktuell befindet sich auch noch eine erweiterte Filesystem-API speziell für PWAs in der Entwicklung, aber das Projekt steht noch in seinen Kinderschuhen.
Cookies kennt ihr sicher alle von diesen tollen Bannern, die man inzwischen auf jeder Website findet und wegklickt, ohne sie zu lesen. Das sind kleine Text-Snippets, die von einem Webserver in eurem Browser hinterlegt werden können, um bestimmte Daten abzuspeichern, zum Beispiel, ob ihr in eine Website eingeloggt seid, oder nicht. Das ist eine sehr alte und für unsere Zwecke nicht besonders relevante Technologie.
LocalStorage ist eine API, mit der sich Schlüssel/Wert-Paare ähnlich wie in einem Objekt in einem für die jeweilige Website gültigen persistenten Speicher schreiben lassen. Auch diese API ist schon recht alt und erfreut sich dadurch großer Unterstützung, allerdings ist sie sehr eingeschränkt, weil sie nur Strings abspeichern kann, d.h. alle eure Werte werden zu Strings konvertiert.
Die Verwendung von LocalStorage ist sehr einfach: mit
window.localStorage.setItem(schlüssel, wert) legt ihr ein Schlüssel/Wert-Paar
an, wobei wert immer ein String sein sollte, denn ansonsten wird er
automatisch in einen String konvertiert. Anhand des übergebenen Schlüssels (auch
ein String) könnt ihr den Wert dann mit window.localStorage.getItem(schlüssel)
wieder auslesen.
Achtung:
Das window-Objekt existiert in Node nicht! Deshalb funktioniert
dieses Beispiel auch nur im Browser. Außerdem kann es unter bestimmten Fällen
vorkommen, dass ihr keinen Zugriff auf LocalStorage bekommt – verwendet daher
einen try…catch-Block, um mit eventuellen Fehlermeldungen
umzugehen und keinen Absturz eures Programms herbeizuführen.
Wenn ihr dieses Beispiel (über einen lokalen Webserver) in eurem Browser öffnet,
könnt ihr sehen, dass der Wert der dark-Variable bestehen bleibt, auch wenn
ihr die Seite aktualisiert, oder schließt und wieder öffnet:
<!DOCTYPE html>
<html lang="en" dir="ltr">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>LocalStorage Test</title>
<style media="screen">
body.dark {
background-color: black;
color: #f9f9f9;
}
</style>
</head>
<body>
<h1>Hier ist eine Überschrift!</h1>
<p>Klicke auf den Button unten, um den Dark-Mode an oder auszuschalten.</p>
<p>Der Dark-Mode ist momentan <span id="darkState">aus</span></p>
<button type="button">Dark-Mode Toggle</button>
<script>
const button = document.body.querySelector('button');
const output = document.getElementById('darkState');
function setDarkMode(val) {
if (val) {
document.body.classList.add('dark');
output.innerText = 'an';
} else {
document.body.classList.remove('dark');
output.innerText = 'aus';
}
}
function handleError(err) {
console.error(err);
// Falls wir nicht auf LocalStorage zugreifen können, sagen wir bescheid
output.innerText('in deinem Browser nicht unterstützt');
}
// LocalStorage kann manchmal fehlschlagen, deshalb try…catch
try {
// Hier lesen wir den Wert mit dem Schlüssel "dark" im LocalStorage aus
const dark = window.localStorage.getItem('dark');
// Falls der Wert undefined, oder nicht der String "false" ist, aktivieren wir den Dark-Mode
if (dark && dark !== 'false') setDarkMode(true);
else setDarkMode(false); // ansonsten nicht
} catch(err) {
handleError(err);
}
button.addEventListener('click', () => {
try {
// Hier lesen wir den Wert mit dem Schlüssel "dark" im LocalStorage aus
const dark = window.localStorage.getItem('dark');
// Falls der Dark-Mode aktiv ist, deaktivieren wir ihn
if (dark && dark !== 'false') {
setDarkMode(false);
// hier speichern wir den neuen Wert im LocalStorage ab, es funktionieren nur Strings!
window.localStorage.setItem('dark', 'false');
} else { // ansonsten aktivieren wir ihn
setDarkMode(true);
// hier speichern wir den neuen Wert im LocalStorage ab, es funktionieren nur Strings!
window.localStorage.setItem('dark', 'true');
}
} catch (err) {
handleError(err);
}
});
</script>
</body>
</html>Wie ihr sehen könnt ist LocalStorage für einzelne und kleine Daten eine sehr einfache und schnelle Lösung, aber selbst für eine einfache Todo-App reicht das schon nicht mehr aus.
Deshalb gibt es IndexedDB – eine eigene Datenbank-API für euren Browser. Diese erlaubt euch das Anlegen und Abspeichern großer Datenmengen in allen möglichen Formaten (sogar Binärdateien wie Bilder werden unterstützt!), sowie die relationale Verbindung dieser Daten miteinander (ein Projekt enthält viele Todos, etc.) und Hochleistungssuchen innerhalb dieser Daten, was zum Beispiel gut ist, um Statistiken zu erstellen, Suchfunktionen einzubauen, etc. Eigentlich die ideale Lösung für PWAs, so lange der Nutzer nicht die Möglichkeit haben sollte, diese Daten auf seiner Festplatte zu finden und in einem anderen Programm zu öffnen.
Inzwischen wird diese API von allen großen Browsern bis auf Internet Explorer unterstützt, weshalb ihr sie für eure Apps ohne bedenken einsetzen könnt. Der einzige Nachteil von IndexedDB ist, dass es eine sehr komplizierte API ist. Es ist also schwierig direkt damit zu arbeiten – aber keine Sorge, dafür gibt es Libraries, die es uns deutlich angenehmer machen. 😉
Aber Amadeus, was ist mit Servern?
Ein ganz anderer Ansatz ist es, die Daten nicht auf dem Gerät des Nutzers zu speichern, sondern auf einem externen Server, auf dem eine „richtige“ Datenbank läuft. Das hat eine ganze Reihe von Vorteilen: die Daten können zwischen Geräten synchronisiert werden, die Daten können nicht vom Nutzer „aus Versehen“ gelöscht werden, die Daten können zwischen Nutzern der App geteilt werden, die Daten können zur Analyse und als Einnahmequelle verwendet werden, und so weiter und so fort.
Allerdings hat all das auch einen gewaltigen Haken: ihr braucht einen Server.
Warum besser alles Client-seitig machen?
Deshalb halte ich es für die beste Idee, alles was geht im Client zu machen. Dadurch stellt ihr automatisch sicher, dass eure App auch ohne Internetverbindung funktioniert, ihr die DSGVO einhaltet, und ihr euch nicht auch noch darum kümmern müsst, ein Backend zu programmieren und zu warten.
Dank IndexedDB habt ihr mehr als genug Power zur Verfügung, um eure Apps umzusetzen. Datenbanksysteme sind schwer, und das ist nur der Anfang: ihr braucht Sicherheits-, Authentifizierungs-, und Authorisierungssysteme, je nach Größe eurer App vielleicht sogar Proxy-Server und Load-Balancer, kurzgesagt, es wäre einfach viel zu viel für eure erste App. 😉
Was geht Client-seitig nicht?
Allerdings hat es auch Einschränkungen, ohne ein Backend auszukommen. Hier sind einige davon:
- Keine Synchronisierung zwischen Geräten
- Kein „Teilen“ von Todos zwischen mehreren Nutzern
- Keine Push-Benachrichtigungen, Reminder oder Ähnliches
Wie kann man manche dieser Limitationen umgehen?
Weil diese Einschränkungen aber bekannt sind, gibt es inzwischen auch für viele von ihnen externe Lösungen. Beispielsweise gibt es Dienstleister, mit denen ihr in den Genuss eines Backends kommen könnt, ohne ein Backend erstellen zu müssen (natürlich gegen Bezahlung). Auch gibt es immer mehr Mittel und Wege, kreativ um diese Einschränkungen herumzuarbeiten. Wer sich dafür interessiert kann sich über das Serverless-Movement informieren. Für diesen Kurs gehen diese Dinge aber etwas zu weit.
Achtung:
Falls ihr jemals mit externen APIs arbeitet, beachtet bitte, dass ihr eure API-Keys mit höchster Sorgfalt behandeln solltet. Falls es sich um Private-Keys handelt, dürfen sie auf keinen Fall in eurem clientseitigen Code, oder Git-Repository auftauchen! Das ist, als würdet ihr das Passwort zu eurem Online-Banking im Internet veröffentlichen.
Baut eure Anwendungen also so, dass sie zu 100% im Client funktionieren. Weitere Funktionalität könnt ihr dann zu einem späteren Zeitpunkt noch immer hinzufügen, wenn ihr ein breiteres Wissen habt.
Was ist Dexie und wie benutzt man das?
Wie bereits angemerkt, ist IndexedDB nicht besonders einfach zu verwenden, und schon gar nicht für jemanden, der nur sehr wenig Erfahrung mit Datenbanken hat. Um mit diesem Problem umzugehen, weil ja kein Weg wirklich um die Verwendung von IndexedDB herumführt, wenn man im Browser lokal Daten persistent abspeichern möchte, gibt es Libraries wie Dexie, die es uns deutlich einfacher machen, mit IndexedDB umzugehen.
Um mit Dexie eine neue Datenbank anzulegen, müsst ihr zunächst Dexie zu eurem Vue-Projekt hinzufügen:
$ npm install dexieDadurch wird Dexie als eine Abhängigkeit in eurer package.json gelistet und
ihr könnt Dexie in eurem Projekt verwenden:
// src/db.js
// Importiere Dexie, damit wir es verwenden können
import Dexie from 'dexie';
// Erstelle eine neue Datenbank mit dem Namen 'MyFriends' und speichere sie in
// der Variablen "db"
const db = new Dexie('MyFriends');
// Version 1 der Datenbank hat eine Tabelle namens "friends" mit Indexen auf
// den Werten 'id', 'name' und 'age'. 'id' ist der primäre Index und wird durch
// das ++ automatisch erhöht, der erste Freund hat also die id 0, der Zweite id
// 1 und so weiter
db.version(1).stores({
friends: '++id, name, age',
});
export default db;Habt ihr eine solche Datenbank angelegt, könnt ihr diese fortan immer mit
import db from '@/db'; dort in eurem Projekt importieren, wo ihr sie benötigt.
Achtung:
Dieses Beispiel funktioniert nur in einem Projekt, das mit der Vue CLI wie in der letzten Session beschrieben erstellt wurde! Falls ihr Dexie in einem anderen Projekt verwenden möchtet, lest euch die Installationsanweisungen in der Dokumentation durch.
Dexie ist also eine Library, die auf der IndexedDB-API aufbaut und uns Entwicklern das Leben erleichtert. Die Library hat sehr viele sehr fortgeschrittene Funktionen und Optionen, die ihr alle in der Dokumentation nachlesen könnt. Ich werde euch hier nur ein kleines Subset dieser Funktionen vorstellen, mit denen ihr anfangen könnt, Todos persistent abzuspeichern. Wenn ihr für bestimmte Funktionalitäten eurer Apps andere Funktionen braucht, findet ihr alles was ihr dazu wissen müsst in der Dokumentation.
Exkurs: try…catch
Wir haben bereits im Abschnitt über Fehlermeldungen von Session 06 darüber gesprochen, dass ein Fehler in JavaScript die Ausführung des gesamten Programms abbricht. In der selben Session haben wir uns auch mit asynchronem Code beschäftigt. Bei der Verwendung von Dexie (und vielen anderen Datenbanksystemen) habt ihr mit beidem zu tun: Funktionen, die nicht sofort einen Wert zurückgeben, sondern eine Promise, also asynchron sind, und Fehlern, die auftreten können, auch wenn ihr euren Code komplett richtig geschrieben habt.
Dank der async/await Syntax von modernem JavaScript könnt ihr diese Fehler
ganz so behandeln, als kämen sie von synchronem Code, das bedeutet mit
try…catch.
Try-Blöcke sind ein spezielles Konstrukt in JavaScript (und vielen anderen Programmiersprachen auch), in denen ihr im Endeffekt sagen könnt: „Probiere diesen Code auszuführen, wenn es nicht klappt (also ein Fehler auftritt), dann mache Folgendes“.
Achtung:
try…catch ist kein Allheilmittel! Ihr solltet diesen Block nur
dann verwenden, wenn ihr wisst, dass etwas schiefgehen kann, das außerhalb
eurer Kontrolle liegt – und dann auch nur diesen speziellen Fehler behandeln.
Alle anderen Fehler, die eventuell durch die Qualität eures Codes verursacht
werden solltet ihr nicht im catch-Block
behandeln, sondern erneut „werfen“. Ausnahme: ihr
veröffentlicht eure Anwendung und habt die Entwicklung abgeschlossen. Dann
solltet ihr alle Fehler abfangen, damit euren Nutzern nicht die App abstürtzt,
aber ihr solltet eure Nutzer dennoch wissen lassen, dass etwas schiefgegangen
ist, z.B. über einen UI-Toast.
In folgendem Beispiel verwenden wir throw um einen Fehler zu werfen, wenn die
age-Eigenschaft des übergebenen Objekts nicht vom Typ „Number“ ist, aber
anstatt das Programm abzubrechen, geben wir eine Fehlermeldung aus, wenn es sich
um diesen TypeError handelt, den wir verursacht haben. Ansonsten behandeln wir
den Fehler nicht und „werfen“ ihn erneut, damit das Programm abbricht:
// trycatch.js
// eine Funktion, die ein Person-Objekt überprüft und einen Fehler wirft, wenn es ungültig ist
function validatePerson(person) {
if (typeof person.age !== 'number') throw new TypeError('Age is not a number!');
}
// Personen, die in ein Array gesteckt werden
const gustav = { name: 'Gustav', age: '22' };
const frida = { name : 'Frida', age: 30 };
const people = [gustav, frida];
// Für jede Person führe diesen Code aus:
for (let i = 0; i < people.length; i += 1) {
const currentPerson = people[i]; // in der 1. Iteration Gustav, in der 2. Frida
try {
// Für Gustav wird hier ein Fehler auftreten, weil age ein String ist und es
// wird sofort der catch-Block aktiviert
// Für Frida wird kein Fehler auftreten und der catch-Block wird ignoriert
validatePerson(currentPerson);
// Dieses Statement wird nur für Frida ausgeführt, weil für Frida kein Fehler auftritt
console.log(`Person ${currentPerson.name} is valid!`);
} catch (error) { // die Variable error (name frei erfunden), enthält immer das Fehlerobjekt, das aufgetreten ist
// Dieser Code wird nur für Gustav ausgeführt
if (error.name === 'TypeError') { // Wir wollen nur spezifische Fehler behandeln
console.log(`Person ${currentPerson.name} is invalid: ${error.message}`);
} else { // Ansonsten haben wir wohl etwas falsch gemacht und sollten Bescheid wissen
throw error; // Der ursprüngliche Fehler wird wieder geworfen, anstatt behandelt und das Programm bricht ab
}
}
}Wie ihr sehen könnt, bekommt der Catch-Block ein Objekt übergeben, das den aufgetretenen Fehler repräsentiert. Dieses Objekt hat zwei für euch wichtige Eigenschaften:
message, die Fehlermeldung als Stringname, der Name des Fehlers, damit ihr Fehler unterscheiden könnt, z.B. TypeError
Diese Daten könnt ihr nutzen, um euren Nutzern sinnvolle Fehlermeldungen zu
geben, oder die Fehler sogar automatisch zu beheben. In unserem Beispiel könnten
wir einfach das age in eine Zahl konvertieren.
Einführung in Datenbanksysteme
Datenbanken sind ein weiteres, hochkomplexes Thema in der Informatik, das sich nicht einfach in einem kurzen Absatz erklären lässt. Aber wie so oft, müsst ihr nur die Grundlogik verstehen, um anfangen zu können, selbst damit zu experimentieren. Der Rest erschließt sich dann hoffentlich während ihr lernt und vor allem übt.
Es gibt verschiedene Arten von Datenbanken, aber der Einfachheit halber gehe ich jetzt speziell auf Beispiele anhand von IndexedDB, bzw. Dexie ein. In Dexie ist eine Datenbank eine Sammlung von sogenannten „Tables“, also Tabellen, die einen einzigartigen Namen haben und in sich beliebig viele Objekte lagern können, die bestimmte Eigenschaften haben.
Nehmen wir als Beispiel eine Liste von Freunden. Dann würdet ihr in eurer Datenbank eine Table mit dem Namen „friends“ anlegen, in der die Freund-Objekte abgespeichert werden können. Dabei hat ein Freund immer einen Namen, ein Alter und ein Foto.
Da ihr wisst, dass ihr eure Freunde entweder nach Alter oder Namen sortieren wollt und zusätzlich den Namen zur Suche verwenden wollt, müsst ihr zudem sogenannte „Indices“ für diese Eigenschaften eurer Objekte anlegen. Einen Index könnt ihr euch wie eine Landkarte vorstellen, in der vermerkt ist, wo genau ein Freund mit bestimmten Namen im Speicher liegt. Ohne Indices wäre es extrem langsam eine Liste von Freunden anzulegen, deren Namen mit dem Buchstaben „P“ beginnen und die nicht älter sind als 30.
Außerdem braucht die Datenbank auch einen Weg zwei Freunde auseinander zu halten, was über den sogenannten „Primärindex“ oder „primary key“ geschieht, in den meisten Fällen einfach eine ID-Eigenschaft. Wichtig ist hierbei, dass der Primärindex einzigartig sein muss, weshalb es Sinn macht, diesen von der Datenbank, also Dexie, verwalten zu lassen. Mit diesen IDs lassen sich Objekte, die in unterschiedlichen Tables liegen auch miteinander verknüpfen.
Habt ihr zum Beispiel eine Table mit Lieblingsgerichten, könnt ihr einfach für jeden eurer Freunde einfach die ID seines oder ihres Lieblingsgerichts in einer „favouriteFood“-Eigenschaft ablegen und müsst dann nicht jeden eurer Freunde mit dem Lieblingsgericht „Tomatenosse“ ändern, wenn es eine Rechtschreibreform gibt und das Gericht jetzt „Tomatensoße“ geschrieben wird. 😉
Welche Tables und Indices es gibt (und welche Daten abgelegt werden können) bestimmt das sogenannte „Schema“ einer Datenbank. Die eigentlichen Daten werden dann mit Hilfe von sogenannten „Queries“ abgefragt, angelegt, und verändert.
Konkretes Beispiel
Wenden wir diese Theorie auf unsere Todo-Apps an, könnte das so aussehen:
// src/db.js
// Dexie importieren
import Dexie from 'dexie';
// Neue Datenbank anlegen (oder bestehende Datenbank laden)
const db = new Dexie('MyAppDatabase');
// Schema der Datenbank definieren
db.version(1).stores({
// Table "todos" anlegen mit Indices auf id (automatisch verwaltet), task, dueDate, und project
todos: '++id, task, dueDate, project',
// Table "projects" anlegen mit Indices auf id (automatisch verwaltet) und name
projects: '++id, name',
});
// Datenbank exportieren, damit sie in anderen Dateien verfügbar ist
export default db;In diesem Skript legen wir eine neue Datenbank an und geben ihr ein Schema, in
dem wir zwei Tables definieren: todos und projects. Außerdem wollen wir
Todos nach task und dueDate sortieren können, sowie leicht alle Todos
anzeigen können, die zu einem bestimmten Projekt project gehören. Deshalb
legen wir zusätzlich zur id-Eigenschaft auch Indices für diese Eigenschaften
an. Projekte sollen nur nach Name sortiert und gefunden werden, desahlb legen
wir nur einen Index für name an (neben der id, die Dexie für uns verwaltet).
Achtung:
Ihr müsst nur die Eigenschaften angeben, für die ihr einen Index braucht! Nach
dem obigen Schema können Todos natürlich auch „description“ oder „done“
Eigenschaften haben, die auch abgespeichert werden. Es wird für diese
lediglich kein Index angelegt. Das ist auch wichtig, wenn ihr mit großen Daten
hantiert: ihr könnt große Daten (z.B. Bilder) in IndexedDB speichern, aber ihr
solltet niemals einen Index für diese Eigenschaften anlegen!
Außerdem solltet ihr beachten, dass Dexie nur Indices für Strings, Numbers,
Arrays und Dates anlegen kann, nicht für Booleans, oder Eigenschaften mit den
Werten null oder undefined.
Jetzt wo unsere Datenbank initialisiert ist, können wir anfangen Daten hinzuzufügen:
// Der Übersichtlichkeit halber habe ich hier den Teil der Component-Instanz weggelassen
// Falls ihr diesen Code übernehmt, müsst ihr die Funktionen natürlich als Methoden im „methods“-Block schreiben
// und diese Funktionen dann in Lifecycle-Hooks oder über Event-Listener aufrufen!
// Datenbank importieren
import db from '@/db'; // '@' ist in Vue-Projekten ein Alias für unseren "src"-Ordner
// Fast alle Operationen in Dexie geben eine Promise zurück, deshalb brauchen
// wir Funktionen, die damit umgehen können
async function addTodo(todo) {
// Datenbankoperationen können schiefgehen: also arbeiten wir mit Try-Catch
try {
// Tables sind Eigenschaften des db-Objekts, die Funktionen wie 'add()' bieten
await db.todos.add(todo); // fügt das Todo hinzu
} catch (err) {
// Idealerweise sollte eure Anwendung mit dem Fehler besser umgehen, als ihn
// nur in die Konsole zu schreiben!
console.log(`Es gab einen Fehler beim Hinzufügen des Todos: ${err.message}`);
}
}
async function addProject(name) {
try {
// Table.add() gibt den neuen primary key, hier die id zurück
const id = await db.projects.add({ name }); // equivalent zu add({ name: name })
return id;
} catch (err) {
// Idealerweise sollte eure Anwendung mit dem Fehler besser umgehen, als ihn
// nur in die Konsole zu schreiben!
console.log(`Konnte Projekt nicht hinzufügen: ${err.message}`);
}
}
// Wir sind in keiner Funktion, müssen also mit der Promise umgehen
// (async Funktionen geben immer Promises zurück)
addProject('allgemein')
.then((result) => {
// result ist die id des erstellten Projekts
// wir setzen dueDate auf -1 weil Booleans nicht indiziert werden können
// sehen wir ein Todo mit einem dueDate von -1 wissen wir, dass es keines hat
addTodo({ task: 'Vorlesung anhören', project: result, dueDate: -1 });
});
addTodo({ task: 'Praxis machen', project: -1, dueDate: -1 });
addTodo({ task: 'Abgabe rocken', project: -1, dueDate: -1 });Dieser Code legt ein neues Projekt an und fügt, sobald das geschehen ist, auch gleich ein neues Todo ein, das in seiner „project“-Eigenschaft die ID des gerade erstellten Projekts verwendet. Außerdem werden noch zwei neue Todos ohne Projekt an.
Nun wo wir Daten haben, können wir diese natürlich auch an anderer Stelle wieder auslesen:
// Der Übersichtlichkeit halber habe ich hier den Teil der Component-Instanz weggelassen
// Falls ihr diesen Code übernehmt, müsst ihr die Funktionen natürlich als Methoden im „methods“-Block schreiben
// und diese Funktionen dann in Lifecycle-Hooks oder über Event-Listener aufrufen!
// Datenbank importieren
import db from '@/db';
async function getData() {
try {
const allTodos = await db.todos // gib uns alle Todos
.orderBy(task) // sortiert nach Task
.toArray(); // als array
const allgemeinProjects = await db.projects // gib uns alle Projekte
.where('name') // wo name
.equals('allgemein') // gleich allgemein
.toArray(); // als Array
const todosInAllgemein = await db.todos // gib uns alle Todos
.where('project') // wo project
.equals(allgemeinProjects[0].id) // gleich der ID des ersten Projekts in allgemeinProjects
.toArray(); // als Array
const todosMitVorlesung = await db.todos // gib uns alle Todos
.where('task') // wo task
.startsWithIgnoreCase('vorlesung') // mit "vorlesung" beginnt und ignoriere dabei Groß/Kleinschreibung
.sortBy('dueDate') // als Array aufsteigend nach dueDate sortiert
console.log(allTodos, allgemeinProjects, todosInAllgemein, todosMitVorlesung);
} catch (err) {
console.log(`Could not get data: ${err.message}`);
}
}
getData();Wie ihr seht, könnt ihr dank des Query-Systems von Dexie eure Daten auf viele verschiedene und komplexe Arten und Weisen durchsuchen. Alle Optionen findet ihr wie immer in der Dokumentation von Dexie.
Dort könnt ihr auch nachlesen, welche Methoden euch zur Verfügung stehen, um Daten einzufügen, zu manipulieren und zu löschen:
- Table.add() um Objekte hinzuzufügen
- Table.get() um ein Objekt mit seinem Primary Key (der id-Eigenschaft in unserem Beispiel) zu „holen“
- Table.update() um ein Objekt anhand seines Primary Keys zu verändern
- Table.delete() um ein Objekt anhand seines Primary Keys zu löschen
Dexie ist sehr mächtig und wirkt daher etwas einschüchternd, aber ihr werdet wie so oft die meisten Funktionen für eure erste App nicht brauchen. Überlegt euch einfach ganz klar, welche Daten ihr habt und wie diese Daten miteinander zusammenhängen, sowie die Art und Weise wie ihr diese Daten darstellen / sortieren möchtet. Das gibt euch praktisch das Schema schon vor.
Der Rest geht mit den Funktionen, die ich euch hier vorgestellt habe ganz
einfach – achtet bitte nur darauf, dass ihr try…catch verwendet, damit
eventuelle Fehler, die leider in manchen Browsern auftreten können, rechtzeitig
abgefangen und behandelt werden. Damit das funktioniert, müsst ihr auch
async/await benutzen, da die meisten Operationen in Dexie asynchron ablaufen
und Promises zurückgeben.
Falls ihr in konkreten Fällen Hilfe braucht, wendet euch einfach an mich, aber versucht zumindest vorher mit Hilfe der Dokumentation eine eigene Lösung zu finden, auch wenn das weniger bequem erscheint. 😉
Warum ist es schwierig erst beim "Schließen" zu speichern?
Wir wissen jetzt also, wie wir Daten persistent abspeichern können, aber wann ist der richtige Zeitpunkt dafür?
Diese Frage lässt sich vergleichsweise leicht beantworten, wenn man sich ansieht, wie Menschen mit ihren Apps / Browsern umgehen. Wir sind es heutzutage gewohnt, dass die Dinge, die wir tun automatisch und ohne unser Zutun abgespeichert werden. Niemand würde eine App benutzen, bei der jedes Mal, nachdem ein Todo abgehakt wurde, auf einen „Speichern“-Button geklickt werden müsste.
Also macht es Sinn einfach nach jeder Aktion, die einen bleibenden Effekt haben soll, zu speichern. Das bedeutet: wenn ein Todo abgehakt wird zum Beispiel, oder wenn der Nutzer ein neues Todo anlegt.
Diese Fälle sind einfach, denn es gibt eine klare Aktion, also ein klares Event, auf das man reagieren kann. Was ist aber, wenn es nicht so klar ist – oder schlimmer: wenn man nicht die Zeit hat. Was ich damit meine?
Stellt euch vor eure App hat einen Timer, der mitläuft während an einem Todo gearbeitet wird. Eigentlich wäre es logisch nur dann die „verbrauchte“ Zeit abzuspeichern, wenn der Timer gestoppt wird. Aber was, wenn der Nutzer die App schließt, ohne den Timer zu stoppen? Dann wären die Daten verloren.
Aber Amadeus, das Schließen der App ist doch ein klares Event, ich kann doch einfach dann speichern!
Leider ist das nicht so einfach. Wie wir gesehen haben, sind die Speicherfunktionen von Dexie asynchron – das bedeutet, ihr könntet die Operation starten wenn die App geschlossen wird, aber sie würde abgebrochen werden, bevor sie abgeschlossen ist, da das Schließen der App ja nicht darauf wartet, bis eure Operation fertig ist.
Außerdem ist es schwierig zu erkennen, wann die App geschlossen wird. Es gibt
zwar Events wie beforeunload oder unload, aber man kann sich nicht auf diese
verlassen, da sie zum Beispiel nicht gesendet werden, wenn ein Nutzer eure App
über die App-Übersicht auf iOS oder Android schließt.
Deshalb ist es besser nicht zu versuchen, etwas zu speichern, wenn die App beendet wird. Stattdessen könnte man zum Beispiel abspeichern, dass ein Timer gestartet wurde und wann er gestartet wurde. Wird der Timer dann gestoppt, speichert man ab, dass er gestoppt wurde. Wird die App geschlossen, während der Timer noch läuft, sieht man beim nächsten Öffnen, dass der Timer noch nicht gestoppt wurde und kann anhand der Differenz zur gespeicherten Startzeit und der aktuellen Zeit sehen, wie viel Zeit vergangen ist und den Timer mit diesem Wert neu starten.
Tipp:
Falls ihr doch einmal einen Weg braucht, um eine Operation auszuführen bevor
ein Nutzer eure App schließt, benutzt das visibilitychange Event
und überprüft dort, ob document.visibilityState === 'hidden' –
das bedeutet, dass der Nutzer eure App nicht mehr sehen kann, weil sie z.B.
minimiert ist, oder er zu einer anderen App gewechselt hat. Falls das der Fall
ist könnt ihr synchrone Operationen ausführen, zum Beispiel kritische
Daten in LocalStorage schreiben und beim nächsten Laden / Öffnen der App in
IndexedDB übertragen.
Exkurs: Statische Websites
Die Techniken und Technologien, die ihr bisher in diesem Kurs gelernt habt, eignen sich nicht nur für die Entwicklung von PWAs, sondern auch für herkömmliche Webseiten, wie zum Beispiel eure Portfolio-Seiten.
Natürlich unterscheiden sich solche Seiten im Aufbau etwas von Apps, aber im Endeffekt sind es am Ende des Tages auch nur statische HTML-Dateien auf einem Webserver. Das ist ein wesentlicher Unterschied zu dynamischen Webseiten, die zum Beispiel von WordPress, Drupal und Typo3 verwaltet werden, denn diese Seiten werden auf den Servern erst dann von Daten aus einer Datenbank generiert, wenn ihr sie anfragt.
Beide Modelle, also statische und dynamische Webseiten haben Vor- und Nachteile, aber vor allem für unsere Zwecke, zum Beispiel für einen Blog oder ein Portfolio reichen statische Webseiten vollkommen aus, sind einfacher zu erstellen und günstiger zu hosten und am Laufen zu halten.
Statisch bezieht sich hierbei lediglich auf die Dateien auf dem Server, nicht auf die Daten, Animationen, oder anderen Inhalte der eigentlichen Seite.
Während dynamische Seiten mit großen Content-Management-Systemen lange Zeit im Trend lagen, besinnen sich immer mehr Entwickler und Unternehmen zurück auf die Anfänge des Internets: also statischen Seiten. Dennoch möchten sie nicht auf moderne Features wie ein CMS und Animationen, oder Live-Inhalte verzichten, weshalb sich eine neue Art entwickelt hat, statische Webseiten zu erstellen: das JAM-Stack.
Was ist das JAM-Stack & Static Site Generation?
Das „JAM“ in JAM-Stack steht für „JavaScript, APIs und Markup“ und soll ausdrücken, dass diese neue Generation statischer Webseiten aus diesen drei Zutaten generiert wird – denn sagen wir es einmal wie es ist: selbst ein Entwickler hat keine Lust, ständig den immer gleichen HTML-Code schreiben zu müssen, nur damit ein neuer Blogeintrag veröffentlicht werden kann.
Im JAM-Stack werden die Nachteile statischer Websites über JavaScript und APIs aufgehoben, indem eine eigentlich statisch auf einem Server liegende Website im Client über JavaScript „dynamisch“ gemacht wird, z.B. indem dem Nutzer Artikel angezeigt werden, die für sie/ihn relevant sind, oder indem die Geschäftstelle, die seiner/ihrer Position am nächsten ist, hervorgehoben wird.
Das Markup dient der einfachen Verwaltung und Bearbeitung von Content. Das kann in der Form von Markdown- oder JSON-Dateien geschehen, die für einen Menschen deutlich einfacher zu schreiben und zu verändern sind, als HTML-Dateien – besonders wenn dieser Mensch kein Entwickler ist.
Ein wichtiger Bestandteil des JAM-Stacks, der so im Namen gar nicht vorkommt, sind auch die sogenannten „Static Site Generators“ oder einfach nur „SSG“, die sich darum kümmern das Markup in eine statische HTML-Website zu kompilieren.
Zur besseren Veranschaulichung, hier ein konkretes Beispiel: ihr habt einen Blog, auf dem ihr regelmäßig Artikel veröffentlicht. Wie ihr es in Webdesign I gelernt habt, habt ihr dafür eine statische Website gebaut, und wenn ihr nun einen neuen Artikel veröffentlichen möchtet, erstellt ihr eine neue HTML-Datei, kopiert den Inhalt eines anderen Artikels, damit ihr eure Navigation und euren Footer habt, und tauscht dann den Inhalt des Artikels mühsam von Hand aus. So weit, so gut.
Dann ist aber plötzlich Silvester und ihr müsst die Jahreszahl in eurem Footer aktualisieren. Das bedeutet, dass ihr in jeden einzelnen eurer Artikel gehen müsst, um in der Kopie des Footers dort die Zahl auszutauschen. Das ist lästig, aber noch möglich. Dann wollt ihr aber eines Tages einen neuen Menüpunkt in eurer Navigation hinzufügen und müsst wieder all eure Artikel verändern und hoffen, dass ihr keinen vergessen habt. Ihr seht: auf lange Sicht ist das ein Albtraum.
Würdet ihr mit einem Static Site Generator arbeiten, hättet ihr ein einziges Template für eure Artikel und eine separate Textdatei für jeden eurer Artikel mit einigen wenigen Metadaten, der sogenannten Frontmatter. Nun braucht ihr nur noch für jeden Artikel eine neue Datei anlegen, in ihr euren Artikel schreiben und zum Schluss den Generator einmal laufen lassen (oder es automatisch geschehen lassen, wann immer ihr einen Commit macht). Der Generator spuckt dann automatisch eine perfekte HTML-Datei für jeden eurer Artikel auf Basis eures Templates aus. Im Umkehrschluss bedeutet das natürlich auch, dass ihr nur einmal das Template verändern müsst, um eine Auswirkung auf allen Artikeln zu sehen.
Natürlich lässt sich dieses Beispiel weiter spinnen, indem ihr zum Beispiel mehrere verschiedene Templates für verschiedene Artikel, oder „normale“ Seiten in eurer Website anlegt. Auch können SSGs euch natürlich vollautomatisch Seiten für alle Artikel zu einem bestimmten Thema anlegen und so weiter.
Diese Kurswebsite funktioniert zum Beispiel genau nach diesem Prinzip. Ich muss für jede Session einfach nur eine Markdown-Datei anlegen und der Static Site Generator, Gridsome in meinem Fall, legt automatisch einen Link dazu auf der Startseite an, generiert das Inhaltsverzeichnis und so weiter und so fort. Ihr könnt euch den Quellcode auf GitLab ansehen, wenn ihr neugierig seid.
Static Site Generatoren gibt es wie Sand am Meer und es werden täglich mehr. Ihr habt im Prinzip freie Wahl zwischen allen von ihnen, am Ende kommt ja doch nur HTML dabei heraus, aber ich kann euch Gridsome und Vuepress nur wärmstens empfehlen, da ihr bereits alles wisst, was ihr wissen müsst, um mit ihnen zu arbeiten, denn sie funktionieren mit Vue-Components. Schaut sie euch einmal an, lest durch die Dokumentation – dann wird euch auffallen, wie umständlich es ist, eine Website von Hand aufzubauen. Interessant ist auch Publii – auch wenn das überhaupt nichts mit Vue zu tun hat und nur begrenzt wie ein herkömmlicher SSG funktioniert.
Wie kann ich damit leicht meine Inhalte verwalten?
Ein großer Vorteil, den Freunde von großen CMS-Systemen immer wieder aufführen, wenn es um statische vs. dynamische Seiten geht, ist dass WordPress & Co. eine Oberfläche anbieten, in der auch Leute die Inhalte einer Website anpassen können, die keine Entwickler sind. Und zugegeben: es ist wirklich praktisch schnell einfach einmal sein Smartphone aus der Hosentasche zu nehmen, sich einzuloggen und einen neuen Artikel zu veröffentlichen, ohne einen Code-Editor öffnen zu müssen.
Das wissen auch die Freunde des JAM-Stacks. Deshalb gibt es inzwischen Lösungen, die uns das auch mit einer über einen SSG generierten statischen Website erlauben, die sogenannten „Headless CMS“-Systeme.
Es gibt zwei verschiedene Arten von diesen Content-Management-Systemen: Git-Based und API-Based.
In Git-Based-Systemen liegt euer Code und Content, wie der Name es schon vermuten lässt, in eurem Git-Repository ab. Git ist also das Backend. Das CMS wird mit eurem Git-Repo verknüpft und bietet dann im Endeffekt eine grafische Oberfläche, in der ihr Dateien im Repo verändert und Commits erstellt. Ist euer Repository dann mit einer CI verknüpft (mehr dazu in der nächsten Session), wird euere Website nach einem Commit automatisch neu generiert und veröffentlicht.
Die Nutzererfahrung ist fast die Selbe wie für eine WordPress oder Typo3 Instanz, mit dem Unterschied, dass ihr am Ende trotzdem immer nur HTML bekommt, was heißt: keine Datenbanken, keine Server, die man Warten muss, und viel, viel weniger Kosten. 👍 Falls euch so ein System interessiert könnt ihr euch Netlify CMS und Forestry einmal näher ansehen.
API-Based-Systeme auf der anderen Seite haben einen eigenen Server, mit einer Datenbank, die als Backend fungiert. Für euch als Individuen sind diese Systeme zu fortgeschritten, aber besonders für größere Unternehmen können sie interessant sein. Beispiele sind hierfür Directus und Strapi.
Aber was, wenn ich ein Backend will?
Diese letzten beiden Systeme könnten auch als Backend für Apps interessant sein, auch wenn ich eher der Meinung bin, dass man für eine App besser ein eigenes Backend schreibt, das man vollständig kontrollieren und anpassen kann. Dafür gibt es natürlich auch eigene Libraries und Frameworks, so wie Meteor und Feathers – und besonders Letzteres kann ich wärmstens weiterempfehlen.
Das Problem ist, dass es sehr aufwändig ist, selbst mit einem so tollen Framework wie Feathers ein eigenes Backend zu programmieren – und nicht nur das, das Backend muss natürlich auch irgendwo auf einem Server gehostet werden, der wiederum Geld kostet und gewartet werden muss. Wie immer gilt: die Sicherheit und Privatsphäre eurer Nutzer haben oberste Priorität. Wenn ihr es euch zutraut, dann probiert es gerne einmal aus mit Feathers ein Backend zu schreiben – es ist einfach nur JavaScript, das dann später in Node ausgeführt wird. Feathers bietet zum Beispiel ein tolles Tutorial, das euch beibringt, euren eigenen Chat-Messenger zu schreiben. Seid euch aber immer dessen bewusst, dass das Backend zu schreiben nur der Anfang der Reise ist und es nicht grundlos Menschen gibt, die auf Systemadministration und Backend-Programmierung spezialisiert sind.
Wie könnt ihr also trotzdem an ein Backend für eure Apps kommen, ohne euch all diesen Stress aufbürden zu müssen? Es gibt inzwischen Dienste, die ein Backend „as a service“ anbieten. Das bedeutet: ihr bezahlt eine Abogebür, die den Ressourcen entspricht, die eure Anwendung verbraucht und bekommt dafür ein allgemeines Backend-System, das ihr wie eine externe API einbinden und benutzen könnt. Ein Beispiel hierfür ist Google’s Firebase.
Mit Firebase habt ihr eigentlich alles, was ihr braucht: Nutzerverwaltung, Authentifizierung, Authorisierung, Datensynchronisierung, Push-Benachrichtigungen, etc. pp. Ich selbst habe damit noch nicht gearbeitet, weil mir das alles als zu unflexibel erscheint und ich mich ungern an eine Firma binden möchte, aber es ist eine Option, die offensichtlich auch von genug Entwicklern genutzt wird – passt nur mit diesen flexiblen Preismodellen auf. Ich habe schon so einige Berichte von Entwicklern gelesen, deren Apps plötzlich über Nacht viral gingen und als sie am nächsten Morgen aufwachten, schuldeten sie Goolge Zehntausende von Dollars.
Falls es euch aber nur darum geht, euren Nutzern die Möglichkeit zu geben Daten zwischen Geräten zu synchronisieren, braucht ihr eventuell gar kein vollwertiges Backend – ihr könntet zum Beispiel auch einfach versuchen die APIs von Cloudanbietern wie Google Drive oder Dropbox in eure App zu integrieren und die Daten eurer Nutzer einfach in deren Cloudspeicher ablegen. Vielleicht könntet ihr sogar einfach Git als ein Backend nutzen, wie es manche Headless CMS tun. Seid kreativ und geht mit den Einschränkungen auf die ihr trefft offen um – es gibt für jedes Problem nicht nur eine, sondern hunderte von Lösungen. Ihr müsst euch lediglich die Lösung aussuchen, die für euren Zweck am besten funktioniert.
Achtung:
Auch bei der Einbindung von Cloud-Provider APIs gilt wieder: passt auf, dass eure Privaten API-Schlüssel NIEMALS in eurem clientseitigen Code oder eurem Git-Repository auftauchen! Und passt bitte mit den „kostenlosen“ Einstiegsangeboten von Backend-as-a-Service-Anbietern auf, die sind meistens alles andere als kostenlos und sind so gestaltet, dass sie euch in das Ökosystem des Anbieters sperren.
Praxis
In der letzten Session habt ihr eure App mit der Vue CLI angelegt und begonnen eure Components von eurem Grafikprogramm als Vue-Components umzusetzen. Diese Arbeit solltet ihr nun fortsetzen und vor allem damit beginnen, eure einzelnen Components zu Views zusammenzusetzen.
Sobald die ersten Views stehen, werdet ihr anfangen, Funktionalität einzubauen
und sehr schnell einen Weg finden müssen, um mit euren Daten umzugehen.
Installiert also Dexie und legt euch wie im Abschnitt zu Dexie oben beschrieben
eine db.js-Datei an, in der ihr das Schema für eure Datenbank definiert.
Tipp:
Es macht Sinn, sich ein Schema für eine Datenbank zunächst auf Papier aufzuzeichnen, damit ihr sicher sein könnt, dass ihr nichts vergesst und schon eine Art visuelle Vorstellung bekommt, wie alles zusammenhängt. Ihr könnt euer Schema natürlich vor der Veröffentlichung eurer App beliebig oft ändern und anpassen, aber wie immer erspart gute Planung euch eine Menge Arbeit. Falls ihr Feedback zu eurem Datenbankschema wollt, könnt ihr mich gerne darum bitten. 😊
So könnt ihr dann diese Datei einfach in den Views eurer App importieren, in denen ihr Daten auslesen, oder abspeichern wollt. Falls ihr eure Daten zentral mit Vuex verwalten möchtet (was sich durchaus anbietet), bedenkt bitte, dass Mutations synchron sein müssen. Falls ihr also in eurem Vuex Store mit Dexie arbeiten möchtet, müsst ihr Actions verwenden. Diese können Mutationen „committen“ und dürfen auch asynchron sein:
// … importe etc. …
const store = new Vuex.Store({
state: {
todos: [],
},
mutations: {
insertTodo(state, todo) {
state.todos.push(todo);
},
},
actions: {
// das ist eine Action, sie kann mit this.$store.dispatch('addTodo', todo) aufgerufen werden
async addTodo({ commit }, todo) {
// wir warten bis das Todo in die Table "todos" eingefügt wurde
const id = await db.todos.add(todo);
// wir combinieren das ursprüngliche todo mit der neuen id
const todoWithId = { ...todo, id };
// und fügen dieses dann in das Array innerhalb unseres states ein
commit('insertTodo', todoWithId);
// nun aktualisieren sich alle Vue-Components, die this.$store.state.todos
// verwenden automatisch und beinhalten das neue Todo
}
}
});Während der Entwicklung empfehle ich es, eure App immer in einem Inkognito-Tab offen zu haben, damit alle Daten, auch die Persistenten, gelöscht werden, sobald ihr den Tab schließt.
Ihr könnt diese Daten aber auch manuell über die Dev-Tools in Chrome wieder löschen (und einsehen). Öffnet dazu die Entwicklerwerkzeuge, indem ihr irgendwo auf der Seite rechtsklickt und „Untersuchen“ auswählt und wählt in der Leiste ganz oben den Reiter „Application“ aus (er kann sich eventuell auch hinter dem „»“-Symbol verstecken).
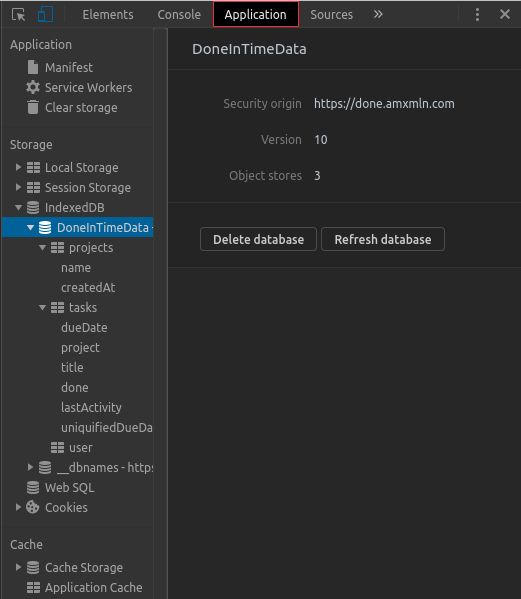
Hier könnt ihr die Daten in IndexedDB und LocalStorage einsehen, verändern und manuell wieder löschen.
Tipp:
Es ist wichtig, dass ihr immer mit einer „frischen“ Datenbank entwickelt, damit keine Fehler auftreten, die eventuell durch veraltete Daten, etc. verursacht werden. Daher der Tipp mit dem Incognito-Tab. Falls ihr das nicht machen wollt, leert eure Datenbank einfach in regelmäßigen Abständen manuell über die Devtools.
Führung durch den Code von Done In Time
Für diejenigen, die es interessiert werde ich am Anfang dieser Praxiszeit durch den Code von Done In Time gehen und zeigen, wie so eine fertige App aussehen kann. Nehmt dieses Angebot vor allem dann wahr, wenn ihr euch noch nicht so ganz sicher seid, wie alles zusammenhängt.
Jetzt wisst ihr wirklich alles, was ihr braucht, um eure Apps zu programmieren. In der nächsten Session sehen wir uns an, wie ihr sie „verpacken“ und schließlich veröffentlichen könnt – und wie man das sogar kostenlos bewerkstelligen kann. 🎉